# Sesión 3 {#s3-p1}

```{r echo=FALSE}
source('global.R')
```

### Conceptos clave previos
Antes de adentrarnos en la ejecución matemática y visual del análisis de
correspondencias, es fundamental que repasemos cuatro conceptos estadísticos
sobre los que se cimenta esta técnica:
- **Frecuencia observada y esperada:** La *frecuencia observada* es el recuento
real de casos empíricos que obtenemos en nuestra tabla de contingencia (las
respuestas directas de nuestra encuesta). Por otro lado, la *frecuencia
esperada* es el recuento teórico que deberíamos encontrar en cada celda si no
existiera absolutamente ninguna relación (independencia estadística) entre las
variables de fila y columna.
- **Residuo:** Es la diferencia matemática entre lo que observamos en la
realidad y lo que esperábamos observar de forma teórica. Un residuo positivo
señala una "atracción" o asociación mayor de lo normal entre dos categorías,
mientras que un residuo negativo indica una falta de vinculación o
"repulsión".
- **Prueba** $\chi^2$ (Chi-cuadrado): Es el contraste estadístico que evalúa el
conjunto total de los residuos de nuestra tabla. Nos permite confirmar si las
discrepancias entre lo observado y lo esperado son lo suficientemente grandes
como para descartar que sean fruto del azar, validando así que existe una
asociación significativa en el mercado.
- **Mapa cartesiano:** Es el producto estrella del análisis de correspondencias.
Consiste en la proyección geométrica bidimensional (el plano formado por los
ejes coordenados) de las relaciones ocultas en la tabla de contingencia. En
este mapa, la inercia y los residuos se traducen en distancias y ángulos,
permitiéndonos leer visualmente el posicionamiento competitivo de forma
intuitiva.
### El concepto de distancia y mapa cartesiano
Algunas consideraciones sobre la representación gráfica de dos variables en un
plano cartesiano
- X -\> latitud
- Y -\> longitud
- X no tiene porqué estar medida en igual escala que Y, de modo que sólo
interpretamos distancias
```{r}
df <- readRDS('data/distancias.rds')
kable(df)
datos <- as.matrix(df[, -1])
rownames(datos) <- colnames(datos)
fit <- cmdscale(datos, eig = TRUE, k = 2)
# Gráfico de la solución
x <- fit$points[, 2]
y <- fit$points[, 1]
# Generate the plot using modern ggplot2 syntax
ggplot(data = datos, aes(x = x,y = y,label = colnames(datos))) +
geom_text(color = "black",vjust = 0,nudge_y = 0.5) +
labs(x = "Coordenada 1", y = "Coordenada 2") +
theme_minimal()
```
## Introducción a la técnica del análisis de correspondencias simple
El análisis de correspondencias (CA) es una técnica de interdependencia cuyo
objetivo es la representación geométrica de las relaciones bidimensionales
derivadas de una tabla de contingencia.
 Trabaja con variables categóricas o no métricas (frecuencias,
recuentos), y nos permite pasar "del caos de los datos a la claridad de un
mapa". Su principal ventaja es que nos ayuda a visualizar la asociación o
similitud entre los niveles de las variables de fila y columna basándose en el
concepto de distancias (distancia $\chi^2$).
### Planteamiento del problema a resolver (Caso HATCO)
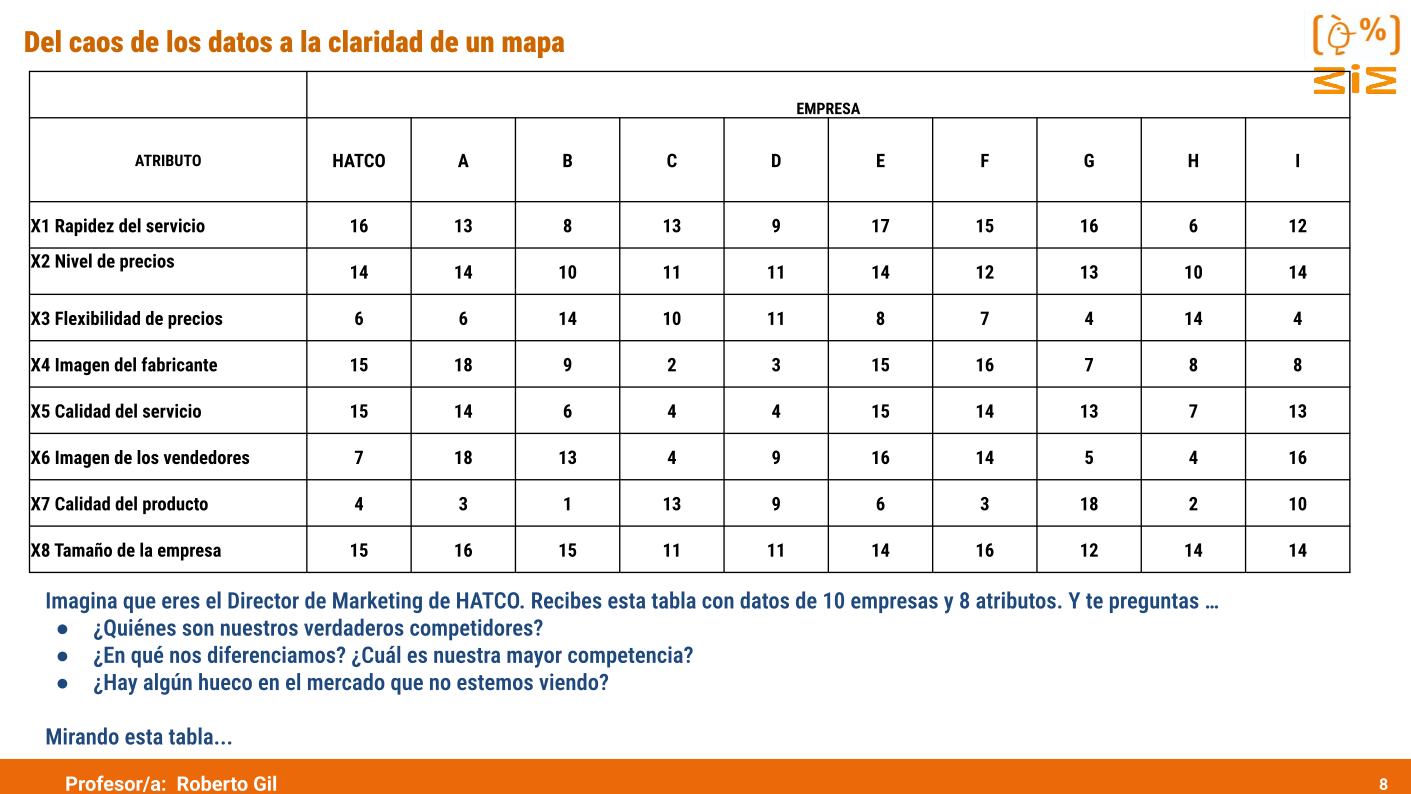
Imagina que eres el Director de Marketing de HATCO. Has identificado a 9
competidores principales (empresas A hasta I) y has pedido a tus clientes que
asocien a estas empresas (incluyendo la tuya) con 8 atributos competitivos:
- `x1`: Rapidez del servicio
- `x2`: Nivel de precios
- `x3`: Flexibilidad de precios
- `x4`: Imagen del fabricante
- `x5`: Calidad del servicio
- `x6`: Imagen de los vendedores
- `x7`: Calidad del producto
- `x8`: Tamaño de la empresa
Nuestras preguntas estratégicas son:
1. ¿Quiénes son nuestros verdaderos competidores?
2. ¿En qué nos diferenciamos?
3. ¿Hay algún hueco en el mercado que no estemos cubriendo?
Sin embargo hay que ser cuidadoso respecto al sentido del análisis en función de
la representación de los datos. En nuestro ejemplo debes verificar teóricamente
que …
- Los poseedores de los atributos son comparables respecto a esos atributos.
- Confirmar que las empresas A,B, ..., I son efectivamente competidoras de
HATCO.
- Que basan su diferenciación en los atributos X1 a X8.
- El listado de atributos debe ser exhaustivo y no dejamos ninguno relevante
para la caracterización de las empresas.
## Preparación del entorno y los datos
Vamos a cargar las librerías necesarias y a leer nuestra matriz de datos. En
este caso, usaremos el paquete `FactoMineR` para los cálculos matemáticos y
`factoextra` para extraer visualizaciones modernas basadas en `ggplot2`.
```{r}
# Load the contingency table (assuming the CSV has companies as columns and attributes as rows)
# For reproducibility, we structure the matrix directly if the CSV is not present
hatco_matrix <- matrix(
c(
16, 13, 8, 13, 9, 17, 15, 16, 6, 12,
14, 14, 10, 11, 11, 14, 12, 13, 10, 14,
6, 6, 14, 10, 11, 8, 7, 4, 14, 4,
15, 18, 9, 2, 3, 15, 16, 7, 8, 8,
15, 14, 6, 4, 4, 15, 14, 13, 7, 13,
7, 18, 13, 4, 9, 16, 14, 5, 4, 16,
4, 3, 1, 13, 9, 6, 3, 18, 2, 10,
15, 16, 15, 11, 11, 14, 16, 12, 14, 14
),
nrow = 8, byrow = TRUE,
dimnames = list(
c("x1", "x2", "x3", "x4", "x5", "x6", "x7", "x8"),
c("hatco", "A", "B", "C", "D", "E", "F", "G", "H", "I")
)
)
# Convert to table object
hatco_table <- as.table(hatco_matrix)
kable(hatco_table)
```
### Visualización exploratoria
💡 Antes del análisis matemático, un `balloonplot` nos ayuda a ver gráficamente
la tabla de frecuencias absolutas: a mayor diámetro del círculo, mayor es la
asociación mencionada por los clientes. Estos aspectos son típicas tareas de un
buen analista que busca la mejor representación (la más visual) para su cliente.
```{r}
# Visualizing the contingency table
balloonplot(
t(hatco_table),
main = "Brand vs Attribute Frequency",
xlab = "Company",
ylab = "Attribute",
label = TRUE,
show.margins = TRUE,
dotcolor = "lightsalmon")
```
## Prueba de homogeneidad (Chi-cuadrado)
Antes de mapear, debemos confirmar empíricamente que existe dependencia
estadística entre las filas (atributos) y las columnas (empresas). La hipótesis
nula ($H_0$) es la independencia: las empresas no se diferencian por estos
atributos.
```{r}
# Perform Chi-Square test on the contingency table
output.chisq_test <- chisq.test(hatco_table)
print(output.chisq_test )
```
Al obtener un *p-value* \< 0.05, rechazamos $H_0$. Existe una asociación
significativa entre las marcas y los atributos. Podemos proceder a mapear.
> ¿Si no podemos rechazar la $H_0$ no se debe seguir adelante? No hay una
> respuesta verdadera. Es claro que no habrán relaciones de mucho poder, pero
> las relaciones se reprfesentan en el plano de igual forma.
🤔 ¿Qué marcas o qué atributos determinana las diferencias? Esta es la primera
pregunta a resolver y para ello nuestra respuesta comienza en el análisis de los
residuos.
### Residuos de la tabla
Una vez confirmado que existe una relación significativa, el primer paso es
explorar los residuos. Estos representan la diferencia entre las frecuencias
observadas en nuestra muestra y las frecuencias que esperaríamos encontrar si
las variables fueran totalmente independientes (frecuencias esperadas).
```{r}
# Accessing raw residuals from the chi-square object
kable(round(output.chisq_test$residuals, 3))
```
### Residuos estandarizados
Para identificar con precisión qué celdas específicas generan la asociación,
calculamos los residuos estandarizados (o estudentizados). Estos residuos
funcionan como una puntuación Z, permitiéndonos realizar comparaciones
estadísticas directas entre celdas:
- **Valores \> 1.96:** Indican que la frecuencia observada es significativamente
superior a la esperada (hay "exceso" de casos en esa celda).
- **Valores \< -1.96:** Indican que la frecuencia observada es
significativamente inferior a la esperada (hay "defecto" de casos en esa
celda).
Estos valores nos permiten señalar las celdas que realmente "rompen" la
hipótesis de independencia con un nivel de confianza del 95%.
```{r}
# Displaying rounded results for easier interpretation
kable(round(output.chisq_test$stdres, 3))
```
### Masas y perfiles: La base del cálculo de distancias
Antes de que el algoritmo calcule los ejes de nuestro mapa, el análisis de
correspondencias transforma las frecuencias absolutas (los recuentos) en
frecuencias relativas.
Para entender de dónde salen las coordenadas, debemos definir tres conceptos
estructurales:
- **Masa (Mass):** Es la importancia relativa o el "peso" de cada categoría
respecto al total de la muestra (porcentaje sobre el gran total). En el mapa,
una categoría con mucha masa tendrá mayor capacidad para "tirar" del centro de
gravedad hacia sí misma. Tenemos masas de fila (peso de cada atributo) y masas
de columna (peso de cada empresa).
- **Perfil de fila (Row profile):** Nos muestra cómo se distribuyen las
respuestas de un atributo específico entre todas las marcas. Se calcula
dividiendo la frecuencia de cada celda entre el total de su fila (es el
equivalente al porcentaje de fila). La suma de cada perfil de fila siempre es
1 (o 100%).
- **Perfil de columna (Column profile):** Nos indica cómo se compone la
valoración de una marca específica a través de todos los atributos. Se calcula
dividiendo la celda entre el total de su columna (porcentaje de columna). Si
el perfil de columna de una marca es idéntico al perfil medio del mercado (las
masas de fila), esa marca se situará exactamente en el centro del mapa (0,0).
En el análisis de correspondencias, la famosa "distancia $\chi^2$" no es más que
la diferencia matemática entre el perfil de una categoría y el perfil promedio
(su masa).
A continuación, extraemos estos cálculos matriciales en R utilizando la función
`prop.table()` sobre nuestra tabla de contingencia original:
```{r}
# 1. Calculate and display masses (Marginal proportions)
# Row masses: Weight of each attribute
row_masses <- prop.table(margin.table(hatco_table, 1))
cat("--- Row Masses (Attributes) ---\n")
round(row_masses, 3)
# Column masses: Weight of each company
col_masses <- prop.table(margin.table(hatco_table, 2))
cat("\n--- Column Masses (Companies) ---\n")
round(col_masses, 3)
# 2. Calculate Row Profiles (Sum of each row = 1)
# margin = 1 indicates calculations across rows
row_profiles <- prop.table(hatco_table, margin = 1)
cat("\n--- Row Profiles ---\n")
round(row_profiles, 3)
# 3. Calculate Column Profiles (Sum of each column = 1)
# margin = 2 indicates calculations down columns
col_profiles <- prop.table(hatco_table, margin = 2)
cat("\n--- Column Profiles ---\n")
round(col_profiles, 3)
```
### Estimación del modelo
El paquete `ca` ofrece una salida de resultados basada en la escuela francesa.
Desarrollado por Michael Greenacre, uno de los científicos que más ha
desarrollado esta técnica.
```{r}
#| echo: true
# Execute Correspondence Analysis using ca()
ca_greenacre <- ca(hatco_table)
# Display the summary (Inertia, Chi-square, and decomposition)
# This provides the 'Scree Plot' information in table format
summary(ca_greenacre)
```
### Interpretación de la salida `summary(ca_greenacre)`
La salida de este comando es la "caja negra" del análisis. Nos permite validar
si el mapa que estamos viendo es una representación fiel de la realidad o si
estamos perdiendo demasiada información.
#### Bloque de inercia (Principal Inertias)
Esta tabla inicial nos indica cuántas "capas" de información (dimensiones) tiene
nuestra tabla y cuánta importancia tiene cada una.
- **`dim` (Dimension):** El número del eje. El primer eje (`1`) siempre es el
que más información captura, el segundo (`2`) el siguiente, y así
sucesivamente.
- **`value` (Eigenvalue/Inercia):** Es el valor propio de la dimensión.
Representa la cantidad de varianza (inercia) que ese eje es capaz de explicar
de la tabla original.
- **`%` (Percentage of inertia):** Nos da la proporción de la inercia total que
captura ese eje. En investigación de mercados, buscamos que los dos primeros
ejes sumen un porcentaje elevado (idealmente \> 70-80%).
- **`cum%` (Cumulative percentage):** La suma acumulada de los porcentajes
anteriores. Nos ayuda a decidir cuántas dimensiones son necesarias para
entender el fenómeno.
- **`chi2`:** Es la parte de la estadística Chi-cuadrado asociada a esa
dimensión.
- **`scree plot`:** Una representación visual (histograma de puntos) de la
importancia relativa de cada eje.
#### Bloque de filas y columnas (Rows / Columns)
Esta sección es crucial para entender el comportamiento de cada marca o atributo
individualmente. Ambos bloques tienen las mismas columnas:
- **`mass` (Masa):** Indica el peso relativo del punto en la muestra total. Una
masa de `0.150` significa que esa categoría representa el 15% de los datos.
Los puntos con mucha masa tienen más "fuerza" para atraer los ejes hacia
ellos.
- **`qlt` (Quality):** Es la calidad de representación (de 0 a 1000). Nos dice
qué tan bien representado está ese punto en el mapa actual (usualmente las dos
primeras dimensiones).
- *Nota:* Si un punto tiene un `qlt` muy bajo (ej. \< 100), su posición en el
gráfico es engañosa y no deberías sacar conclusiones estratégicas sobre él.
- **`inr` (Inertia):** Es la contribución del punto a la inercia total de la
tabla. Nos dice cuánto "caos" o diferenciación aporta ese punto específico al
mercado. Una marca muy distinta al resto tendrá un `inr` alto.
- **`k=1, k=2` (Coordinates):** Son las coordenadas exactas del punto en el eje
1 y eje 2. Es lo que R utiliza para dibujar el punto en el mapa cartesiano.
- **`cor` (Correlation / Cos²):** Mide la asociación entre el punto y el eje
específico. Un `cor` alto en el eje 1 significa que ese punto es el que mejor
define lo que ese eje representa (ej. el eje del precio).
- **`ctr` (Contribution):** Indica cuánto contribuye ese punto a la construcción
de ese eje concreto. Ayuda al investigador a ponerle "nombre" a los ejes (ej.
"si las marcas con más `ctr` en el eje 1 son las más caras, llamaremos al eje
1 'Eje de Precio'").
Cuando analices la tabla, sigue este orden lógico: 1. Mira el **`%` acumulado**
para saber si tu mapa de 2 dimensiones es suficiente. 2. Observa el **`qlt`** de
las marcas que te interesan; si es alto, puedes confiar en su posición en el
mapa. 3. Usa el **`ctr`** para identificar qué variables son las responsables de
que el mapa tenga esa forma y no otra.
### Visualización
El paquete `ca` original tiene su propia función `plot()` que permite un control
muy preciso sobre el escalado (simétrico, asimétrico, etc.) de los ejes
visuales. Dado que vamos a representar un mapa cartesiano, es importante conocer
las coordenadas. Nos abstraemos al cálculo matemático para su obtención.
```{r}
# Standard Biplot using the ca package's native plotting function
# map = "symmetric" is the standard for market research
kable(ca_greenacre$colcoord)
kable(ca_greenacre$rowcoord)
```
Conocidas las coordenadas, representamos el mapa visual.
```{r}
# Generate the base plot using the ca package with native arrows
plot(ca_greenacre,
main = "Mapa simétrico con vectores (paquete ca)",
map = "symmetric",
col = c("steelblue", "orange"),
col.lab = c("steelblue", "orange"),
pch = c(16, 17),
arrows = c(TRUE, TRUE) # TRUE for rows, TRUE for columns
)
```
### Puntos suplementarios
En la investigación estratégica, a menudo queremos proyectar perfiles teóricos
(como el "Servicio Ideal" o un "Competidor de Referencia") sin que estos
influyan en la construcción de los ejes. En el paquete `ca`, esto se gestiona
mediante los argumentos `supcol` (para columnas suplementarias) o `suprow` (para
filas).
Vamos a proyectar nuestro "Competidor IDEAL" para ver qué distancia existe entre
la percepción actual de HATCO y la perfección teórica.
```{r}
#| echo: true
# 1. Define the ideal profile (high scores in all attributes)
ideal_profile <- c(15, 15 ,15, 15, 15, 15 ,15, 15)
# 2. Bind the ideal profile as the 11th column of our matrix
hatco_extended <- cbind(hatco_matrix, IDEAL = ideal_profile)
# 3. Estimate the model identifying the 11th column as supplementary
# The algorithm ignores this column for inertia calculation but projects it later
ca_sup <- ca(hatco_extended, supcol = 11)
# 4. Summary of the model including supplementary points
# Note that 'IDEAL' will appear in a separate section of the output
summary(ca_sup)
```
### Visualización del posicionamiento IDEAL
Al graficar, el paquete `ca` diferencia automáticamente los puntos activos de
los suplementarios (generalmente usando símbolos o colores distintos) para que
el analista no olvide que ese punto no ha ayudado a "dibujar" el mapa, sino que
solo ha sido "invitado" a la foto.
```{r}
#| echo: true
#| fig-width: 10
#| fig-height: 7
# Plotting with supplementary points
# points = "all" ensures that the supplementary column is displayed
plot(ca_sup,
main = "Map with Supplementary Point (Greenacre style)",
col = c("steelblue", "orange", "seagreen"),
col.lab = c("steelblue", "orange"),
pch = c(16, 17, 18), # 18 (diamond) for the IDEAL point
map = "symmetric",
arrows = c(TRUE,TRUE)
)
```
**Interpretación estratégica:**
Al observar el mapa, el punto **IDEAL** suele situarse cerca del origen. Esto
ocurre porque un perfil que es "bueno en todo" no tiene un sesgo hacia ninguna
dimensión específica (no es especialmente "barato" ni especialmente "rápido"
comparado con el resto, sino que es máximo en todo).
Para HATCO, la clave no es estar necesariamente cerca del centro (donde el IDEAL
se ubica por equilibrio), sino verificar que el ángulo formado entre el vector
de **HATCO** y el del **IDEAL** sea lo más pequeño posible en las dimensiones
que el mercado más valora. \## Decálogo de interpretación del análisis de
correspondencias
Al interpretar el mapa cartesiano, aplicamos estas reglas fundamentales:
1. **El origen (0,0):** Representa el "perfil promedio" del mercado. Puntos
cercanos al centro son poco discriminatorios (no destacan especialmente en
nada o son percibidos como la media).
2. **Distancia al origen:** Cuanto más lejos está una marca o un atributo del
centro, más fuerte es su diferenciación y más contribuye a la inercia del
modelo.
3. **Proximidad intra-grupo:** La proximidad física entre dos marcas (puntos
verdes) indica que los consumidores las perciben como similares (son
competidores directos).
4. **Ángulos inter-grupo (Regla de Oro):** Para relacionar una marca con un
atributo, no miramos solo la distancia física, sino el **ángulo** que forman
al trazar líneas desde el origen (0,0):
- **Ángulo agudo (\< 90º):** Fuerte asociación positiva. (Ej. HATCO y la
Empresa A están muy asociadas a los atributos x4 y x6).
- **Ángulo recto (90º):** Independencia. La marca no destaca ni a favor ni
en contra de ese atributo.
- **Ángulo obtuso/llano (180º):** Oposición o asociación negativa. La marca
se define por *carecer* de ese atributo. (Ej. La Empresa G está
diametralmente opuesta al atributo x3).
### Diagnóstico estratégico para HATCO
- **El Eje del Prestigio (Dimensión 1 - Derecha):** HATCO, A, E y F dominan el
cuadrante asociado a la imagen del fabricante (x4), calidad de servicio (x5) e
imagen de vendedores (x6). Son las marcas *premium*. HATCO debe proteger esta
reputación.
- **El Eje de Eficiencia de Producto (Dimensión 1 - Izquierda):** La empresa G
domina en solitario la calidad pura del producto (x7), distanciándose de la
"imagen comercial".
- **El Eje del Precio (Dimensión 2 - Abajo):** Las empresas B y H compiten
puramente en flexibilidad de precios (x3), siendo las opciones "negociadoras"
o económicas del mercado.




 Trabaja con variables categóricas o no métricas (frecuencias, recuentos), y nos permite pasar “del caos de los datos a la claridad de un mapa”. Su principal ventaja es que nos ayuda a visualizar la asociación o similitud entre los niveles de las variables de fila y columna basándose en el concepto de distancias (distancia
Trabaja con variables categóricas o no métricas (frecuencias, recuentos), y nos permite pasar “del caos de los datos a la claridad de un mapa”. Su principal ventaja es que nos ayuda a visualizar la asociación o similitud entre los niveles de las variables de fila y columna basándose en el concepto de distancias (distancia 


